Kubernetes Meetup Tokyo #2 で LT してきた #k8sjp
最近ちょくちょく人前出るようになったので、ちゃんと記録はしておこうと思いました。
六本木ヒルズの Google で開催された Kubernetes Meetup Tokyo #2 で LT してきました。
最近作った Kubernetes Secret を手軽に扱えるツール k8sec と Go Kubernetes API Client Library を使ったコードの書き方を紹介しました。準備不足感が否めなくて申し訳なかったです…。スライドはこれです。
(R, G, B) = (50, 109, 230) が Kubernetes の色っぽいです。
伝えたかったこととしては、
- Ops だけでなく Dev が叩けるようなインターフェイスにしたい
- シェルスクリプトや書捨てスクリプトで運用するよりは、ちゃんとツールを作ったほうがいい
- API Client Library 使えば、ツール作るのもそう難しくはない
です。
で、こいつが発表中に紹介した k8sec です。Heroku 使ってた人にとっては馴染みやすいと思うのですがどうなんでしょう…。
Kubernetes の運用は自分たちも検証段階ですが、各社それぞれ違った知見を持ちつつ同じような悩みを抱えてたりしているようでした。今回みたいな Meetup や Slack などで情報交換していけるとよさそうです。ありがとうございました。
「クラウド開発徹底攻略」を読んだ
技術評論社さんのクラウド開発徹底攻略 (WEB+DB PRESS plus) を、特集「Docker 実戦投入」を執筆された @spesnova さんよりご恵贈いただきました。ありがとうございます。

おなじみ徹底攻略シリーズということで過去に WEB+DB Press 誌に掲載された記事を再編集したものなんですが、再掲載までおよそ1年分のアップデートが各記事にしっかりと反映されているようでした。クラウドや Docker 界隈は移り変わりが激しいので、最新情報をまとめて書籍でおさらいできるのは非常にありがたいです。
記事は「AWS 自動化」「Docker 実戦投入」といった一歩進んだ実運用の話のほか、Google Cloud Platform と Heroku の入門や BigQuery, Amazon SNS の活用まで、今時のクラウドインフラのトピックが幅広く抑えられています。Docker とか BigQuery とかってよく聞くしググれば情報は出てくるけど、じゃあベストプラクティスは?と言われると見つけにくいところがあります。そういった点で本書は一通りのプラクティスがまとまっており、おすすめです。実際の運用例だけでなく、サービスの哲学や大本の仕組みについて解説されている点も良かったです。
特に Docker 界隈は Kubernetes がメジャーになり、ベストプラクティスがここ1年で大きく移り変わってきた感じがあります。本書の「Docker 実戦投入」はその進化に追従し、全体的に、特に後半の運用話が大幅にアップデートされています。元記事ではオーケストレーションに Capistrano を使っていましたが、本書では全面的に Kubernetes を使うようになっています。そういや当時は Docker Swarm や Kubernetes がベータで、実運用投入するならどれがいいのかと悩んでましたね…。Rails アプリの運用を題材に一通りの操作が抑えてあるので、今時の Docker 事情を知りたい方や Kubernetes 導入を考えている方は参考になると思います。
というわけで、今時のクラウドインフラ事情を掴んでおきたい方、いまはオーソドックスに AWS や Docker を使っているけど一歩進んだ使い方を知りたい方はマストバイな一冊です。 自分も AWS 自動化で触れられているツールや GCP はこれまであまり触ってなかったので、これを期におさらいしておきたいです。
最近書いた Datadog にメトリクスを送りつけるツール
日頃インフラメトリクスの監視には Datadog を使っています。最近せっかくなのでインフラ以外の色々も Datadog で監視したくなったので、メトリクス中継用のツールを2個ほど作りました。せっかくなので紹介します。
SendGrid2Datadog (SendGrid events)
メール配信サービスである SendGrid のイベントを Datadog 上で監視できるようにするやつです。
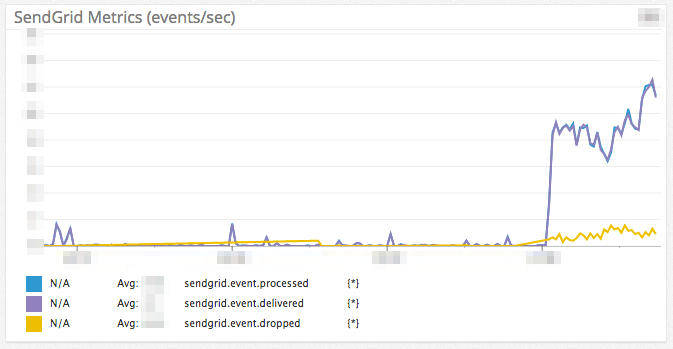
いまどのくらいメールが送られているかというのをパッと確認できるようにしたいと思い作りました。インフラメトリクスが置いてあるダッシュボードにこのグラフを同居させてあるため、DB 負荷が上がった時にも効率よく確認することができます。
SendGrid2Datadog 自体は Heroku 上で動作しています。
実装
SendGrid2Datadog は小さな Web アプリケーション (Ruby + Sinatra) として実装されてます。SendGrid にはメール送信や送信失敗のイベントごとに Webhook を投げる機能があるため、それを受けて都度 Datadog にイベント発生を送信するようにしています。 Datadog への送信は Dogstatsd を使っています。
Spotdog (EC2 Spot Instance History)
AWS EC2 には価格変動型のスポットインスタンスというのがあります。このスポットインスタンスの価格推移を Datadog 上で監視できるようにするやつです。
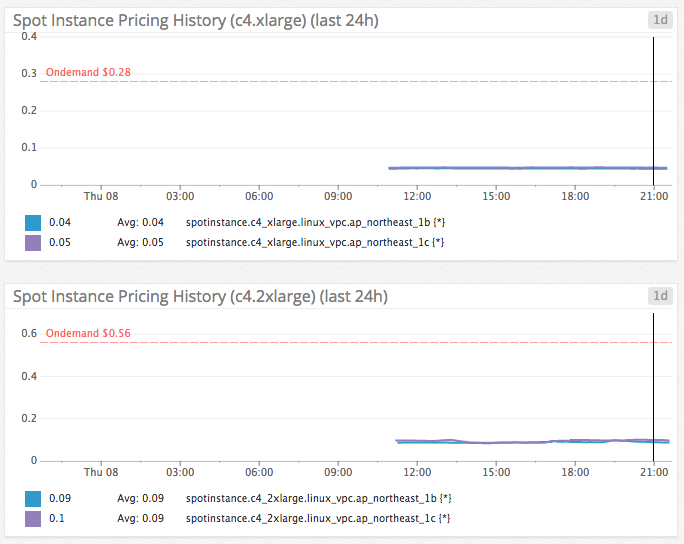
この価格推移グラフ、一応 Management Console にログインすれば見れるのですがまあ面倒です。複数インスタンスタイプの一覧表示とかできません。

なので、Datadog 上で見られるように、自分の好きなようにグラフを組めるように Spotdog を作りました。上の図にあるようにオンデマンド価格を閾値として表示できるため便利です。オンデマンド価格を超えたらアラート飛ばすとかももちろん可能です。
惜しいのは、値が小数点第二位までしか表示できないことでしょうか(グラフ上は反映されてる)。c4.xlarge あたりだと小数点第三位での動きが多いのでそのへん確認できないのはつらいです。まあグラフでだいたいの推移を確認できるのでよいでしょうか。
Spotdog も Heroku 上で動作しています。ただ、こいつは後述するようにコマンドラインツールなので Heroku Scheduler で10分おきに叩くようにしています。
実装
Spotdog は Ruby なコマンドラインツールです。Docker image もあります (quay.io/dtan4/spotdog)。インスタンスタイプや期間を指定すると、AWS の API を叩いてそのあいだの価格推移を取得し、ひとまとめに Datadog へ送信します。 Datadog への送信は Datadog API を使っています。
おわりに
今回は取得するメトリクスの性質が違うこともあって、全く別々に実装しました。Fluentd 噛ますようにするとスマートになるかな?とは思ったのですが普段 Fluentd 使ってないのでスクラッチでサッと実装した次第です。
Terraforming: 既存のインフラリソースを Terraform コードに落としこむ
インフラ界隈のみなさま、 Terraform 使ってますか? 導入したいけど、既存のリソースの管理をどうするか悩んでないですか?
少し前からこの問題を解決する Terraforming というツールを作っていて、今回 v0.1.0 を公開したので紹介します :tada:
https://github.com/dtan4/terraforming
https://rubygems.org/gems/terraforming
![]()
これはなに
Vagrant で有名な HashiCorp が開発している Terraform というインフラをコードで管理するためのツールがあります。 Infrastructure as Code というやつです。 Terraforming は、AWS の API を叩いていま動いている既存の AWS リソースから Terraform のコードを生成するツールです。
インストール
RubyGems として公開されているので、
$ gem install terraforming
Docker Image も用意しているので、そちらを使いたい方は
$ docker pull quay.io/dtan4/terraforming:latest
使い方
予め AWS のクレデンシャルを環境変数に入れておきます。 Mac ユーザなら envchain おすすめです。
export AWS_ACCESS_KEY_ID=XXXXXXXXXXXXXXXXXXXX export AWS_SECRET_ACCESS_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx export AWS_DEFAULT_REGION=xx-yyyy-0
リソース名を指定するだけだと、tf 形式で出力されます。 S3 bucket の場合だと:
$ terraforming s3
resource "aws_s3_bucket" "hoge" { bucket = "hoge" acl = "private" } resource "aws_s3_bucket" "fuga" { bucket = "fuga" acl = "private" }
これを s3.tf とかに書き出せばよいです。
--tfstate オプションをつけると、tfstate 形式で出力されます。
$ terraforming s3 --tfstate
{
"version": 1,
"serial": 1,
"modules": {
"path": [
"root"
],
"outputs": {
},
"resources": {
"aws_s3_bucket.hoge": {
"type": "aws_s3_bucket",
"primary": {
"id": "hoge",
"attributes": {
"acl": "private",
"bucket": "hoge",
"id": "hoge"
}
}
},
"aws_s3_bucket.fuga": {
"type": "aws_s3_bucket",
"primary": {
"id": "fuga",
"attributes": {
"acl": "private",
"bucket": "fuga",
"id": "fuga"
}
}
}
}
}
}
また、tfstate は既存の terraform.tfstate にマージした形で出力することもできます。ちゃんと serial (terraform.tfstate のバージョン番号) もインクリメントされます*1。
$ terraforming s3 --tfstate --merge=/path/to/tfstate
{
"version": 1,
"serial": 89,
"remote": {
"type": "s3",
"config": {
"bucket": "terraforming-tfstate",
"key": "tf"
}
},
"modules": {
"path": [
"root"
],
"outputs": {
},
"resources": {
"aws_iam_user.dtan4": {
"type": "aws_iam_user",
"primary": {
"id": "dtan4",
"attributes": {
"arn": "arn:aws:iam::012345678901:user/dtan4",
"id": "dtan4",
"name": "dtan4",
"path": "/",
"unique_id": "ABCDEFGHIJKLMN1234567"
}
}
},
"aws_s3_bucket.hoge": {
"type": "aws_s3_bucket",
"primary": {
"id": "hoge",
"attributes": {
"acl": "private",
"bucket": "hoge",
"id": "hoge"
}
}
},
"aws_s3_bucket.fuga": {
"type": "aws_s3_bucket",
"primary": {
"id": "fuga",
"attributes": {
"acl": "private",
"bucket": "fuga",
"id": "fuga"
}
}
}
}
}
}
これを terraform.tfstate に上書きすればよいです。
最後に terraform plan を実行して、差分が出ないことを確認して下さい。
$ terraform plan No changes. Infrastructure is up-to-date. This means that Terraform could not detect any differences between your configuration and the real physical resources that exist. As a result, Terraform doesn't need to do anything.
対応している AWS リソース
v0.1.0 時点では以下のリソースに対応しています。
- Database Parameter Group
- Database Security Group
- Database Subnet Group
- EC2
- ELB
- IAM Group
- IAM Group Policy
- IAM Instance Profile
- IAM Policy
- IAM Role
- IAM Role Policy
- IAM User
- IAM User Policy
- Network ACL
- Route53 Record
- Route53 Hosted Zone
- RDS
- S3
- Security Group
- Subnet
- VPC
もちろん鋭意追加予定です。
兄弟分
DNSimple に対応した Terraforming::DNSimple があります*2。 一応プロバイダが違うのでツールを分割したけど、いつかは Terraforming に統合するかもしれません*3。
ここから余談
作ったきっかけ
インターン先*4でインフラをコードで管理しようという機運が盛り上がり、Terraform を導入することになりました。
公開されている中だと、KAIZEN Platform の Terraform 導入事例や CyberAgent の Terraform 導入事例があります。 どちらもインフラ刷新や新規構築のタイミングで Terraform を導入しています。 つまり一からコードを書いてそれを元に Terraform でインフラを構築するということで、 Terraform のユースケースには合っています。
しかし、自分たちは別に刷新のタイミングなんかではなかったので、今動いている既存のインフラをコードに起こす必要がありました。 そこで既存のインフラを Terraform で管理する術を調べていたところ、人間が手作業でやるのは相当厳しいとわかったので生成ツールを作ろうと思い立ったのでした。
Terraform がどうやってインフラを管理しているのか
Terraform は、状態管理用の terraform.tfstate というファイルを用いて自分が管理しているインフラを把握しています。
terraform.tfstate の実体は JSON で、Terraform が管理しているインフラの状態が記述されています。
{
"version": 1,
"serial": 88,
"remote": {
"type": "s3",
"config": {
"bucket": "terraforming-tfstate",
"key": "tf"
}
},
"modules": [
{
"path": [
"root"
],
"outputs": {},
"resources": {
"aws_iam_user.dtan4": {
"type": "aws_iam_user",
"primary": {
"id": "dtan4",
"attributes": {
"arn": "arn:aws:iam::012345678901:user/dtan4",
"id": "dtan4",
"name": "dtan4",
"path": "/",
"unique_id": "ABCDEFGHIJKLMN1234567"
}
}
}
}
}
]
}
terraform plan や terraform apply では、この terraform.tfstate と開発者が書いた tf ファイルを突き合わせることで、どのリソースが増えた消えた変更されたを計算するのです。
既存のインフラリソースを追加する場合は、tf ファイルにそのリソースを書くだけではダメなのです。
terraform.tfstate に記述されていないと、Terraform はそのリソースがないものとみなして新しく作成しようとします。
そのため、同時に terraform.tfstate にも手を加えるする必要があるのです。
ほら、手で JSON を書くのは辛いでしょう? そのための Terraforming なのですよ。
既存のインフラを Terraform で管理する
かなり早い段階でこの問題に触れていたのは下の記事です。
Handling extant resources in Terraform « dan phrawzty's blog
自分もこの記事を見て terraform.tfstate の更新がいることを知ったのでした。
Terraform のリポジトリでも半年前から issue は上がっているのですが、大して進展していません(どこから見つけたのか、Terraforming が登場していたりします)。
Import resources into Terraform · Issue #581 · hashicorp/terraform
ちなみに cookpad が作っている codenize.tools には、我々が求めていた既存インフラの export 機能がちゃんとあります。 もともとは cookpad のインフラをコード化するために作られたツールなので、この機能は必須だったのでしょう。
開発方法
tf はドキュメント化されているのでともかく、tfstate は出力形式がわからなかったので実際にリソースを Terraform で作ってその結果をもとに実装したりしていました。 結構ドキュメント化されていない暗黙の決まりみたいなのが多く(API レスポンスのどのパラメータを tfstate に反映するのだとか)、Terraform 本体のコードもそれなりに読みました。
おわりに
Terraforming という便利ツールを開発した話と、それにまつわるいろいろを書きました。 既存リソースの export 機能、それなりに需要ありそうですがどうなんでしょう…
Issue, Pull Request は大歓迎です!!!ぜひ使ってみてください :tada:
Github の緑化を続けて半年経った
緑化を続けて半年経った pic.twitter.com/79KIRpP8S8
— D端子 (@dtan4) 2014, 11月 175月頃から、「継続的緑化活動」と称して Github の Contribution Graph を埋めるというのを続けています。 そしてつい先日、継続日数 (Current streak) が180日、つまり半年を越えました。 めでたい。

上の Graph は Public Repository への Contribution だけで構成されています。 Private Reposirtory のものは抜いてます。 自分からはログアウトしなくとも Chrome とかのシークレットウィンドウで見られる。
問題点
ただ、Contribution Graph や実際の Activity を見るとわかるように
- (特に8月以降)色が薄い
- 一日に大した活動をしていない
- dotfiles 系の更新とかが多い
- ちゃんとしたプロダクトの開発に手を付けられていない
という状況です。 Graph がすべて緑で埋まるまで残り半年、上記のことを意識して継続的に緑化していきたい所存です。
実は LT していた
今さらですが、9月に行われた RubyHiroba 2014 (投稿現在、見られないけど)で継続的緑化活動について LT していました。 本当に飛び入りで、人生初の LT をしました。 資料を載せておきます。
あと、緑化活動を行う上で目を通しておくべき Github の公式ガイドラインをおいておきます。
Why are my contributions not showing up on my profile? - User Documentation
どういった Activity で緑が増えるのか・増えないのかといったことが書かれています。 fork したリポジトリへのコミットは反映されない*1とか、そういうこと。
*1:本家に PR 投げてマージしてもらえたら反映される
DeployGate@ミクシィのインターンに参加した
8/1 から 9/5 までの5週間、DeployGate@ミクシィのインターンシップに参加してきました。 何をやったかとか感想とかを書いておきたいと思います。
参加の経緯
逆求人イベントに参加して、そこでミクシィ人事の方々と知り合ったのが最初のきっかけです。 自分は、最初からインターンは「1ヶ月スパンの長期で・実際に業務に関わるやつ」に参加したいと考えていましたが、その点ミクシィのインターンは自分の希望にマッチしていました*1。
Internship2014 | 株式会社ミクシィ 学生向けエンジニアイベント
募集部署は数ありますが、その中でも DeployGate は
- 個人的に使っていた
- 開発環境の改善・開発の高速化を目標とするサービスである
という点で興味を持ち、配属を希望しました。
業務
社員と同じように、チームにジョインしてサービスの開発に参加できます。 自分は期間通じてサーバサイド (Rails) の開発をしていました。 新機能の追加から既存箇所の修正・改良まで、いろいろさせて頂きました。 このへん、インターンとはいえ裁量広くさせてもらえます。
DeployGate では Github を用いた Pull Request ベースの開発が行われています。 コミュニケーションツールとしては、Slack とか Sqwiggle とかを取り入れていて楽しい感じでした。 プルリク上では、自分の書いたコードをがっつりと社員さんにレビューしてもらえました。
開発にあたっては、テストファーストを心がけていました。 自分が新たに実装する箇所は勿論ですが、既存箇所に手を加えるところでもテストが不足していたら補完した上で実装に入るようにしていました。 現状どのような仕様になっているのか確認する上でも、役に立ったとは思います。
DeployGate グループ
DeployGate の開発チームはミクシィの中でも独立している感じで、すごくベンチャー感*2に溢れていました。 色々自由な雰囲気でした。
インターン中に開発した機能
色々させてもらったのですが、ここで自分が開発に携わった機能を2つほど紹介しようと思います。
Invite API で DeployGate 未登録の人を招待
DeployGate には、アプリケーション開発者に他の人を招待する Invite API というものがあります。 従来は、API 経由だとすでに DeployGate に登録しているユーザしか招待できませんでした*3。
今回、この Invite API で未登録の人もメールアドレスで招待できるようにしました。
API 書式は従来と変わらず、users に未登録なメールアドレスを指定できるようになっています。
例えば招待したい人たちのアドレスが hoge@example.com, fuga@example.com、 だったとき、curl リクエストは以下のようになります。
# YOUR_API_TOKEN: あなたの API token # YOUR_USER_ID : あなたのユーザ ID # YOUR_APP_ID : 追加対象のアプリ ID (ex. com.deploygate.sample) curl -X POST \ -F "users=[hoge@example.com,fuga@example.com]" \ -F "token=YOUR_API_TOKEN" \ https://deploygate.com/api/users/YOUR_USER_ID/apps/YOUR_APP_ID/members
招待された人たち (hoge@example.com, fuga@example.com) には、アプリへの招待メールが送られます。
そこから DeployGate に登録すると、アプリ開発者として登録された状態で始めることができます。
自分が最初に取り組んだ機能がこれでした。 実際に本番で動いているのを確認できた時は嬉しかったです。
DeployGate 未登録の人をグループに招待する
DeployGate では、現在 Beta Program にてグループ機能を提供しています。 部署単位とかでグループを作成し、グループ内で「開発者」「テスター」という風にチームを作って権限管理を行うことができます。
ここで、部署に新しいメンバーがジョインしたときのことを考えてみましょう。 早速部署のグループに追加し、開発に加わってもらいたいところです。
これまでの DeployGate は、グループに追加できるのは登録済ユーザに限られていました。 そのため、新メンバーをグループに加えるには以下の手順を踏む必要がありました。
- グループの管理者は、新メンバーに「DeployGate に登録してください」とお願いする
- 新メンバーが DeployGate に登録する
- 新メンバーは管理者に自分の ID を伝える
- 管理者は新メンバーの ID をグループに追加する
- さらに新メンバーを適当なチームに加える
1.「登録をお願いする」と3.「ID を伝える」は、メールや口頭で行う必要がありました。 また、登録が済むまで管理者はグループやチームへの追加が行えませんでした。 ここがメンバーが増えた時のネックであり、新メンバーが即座に開発に参加できるとは言いがたい状況となっていました。
そこで今回、DeployGate 未登録のメンバーもメールアドレスでグループやチームへ自由に追加できるようにしました。 新メンバー追加の手順としては以下のようになりました。
- 管理者は新メンバーのメールアドレスをグループに追加する。適宜チームに追加することもできる
- 新メンバーに「グループへの招待」メールが送られる
- 新メンバーはメールに記載されたリンクから登録を行う
- (iOS からの登録の場合)新メンバーは端末にプロファイルインストールを行う

- 登録が完了すると、招待されたグループとチームに所属した状態で開発を始められる!


管理者の手順としては、登録済みユーザ追加の場合と同様のものになりました。 登録完了を待たずにグループへの配置作業を行えます。 新メンバーも最初からグループに所属した状態で登録できるので、即座に開発へ参加することができます。
リリース後に、自分でグループに5人ほど追加する機会があったのですが、実際使ってみると招待を出す側としては随分楽になったと感じました。 より使いやすくなったグループ機能を、ぜひ使ってみてください!
思ったこと
個人開発と業務としてのサービス開発の違い、というのが実感できたように思います。 これまでの個人開発だと、わりと「自分のやりたい」技術メインで実装しがちでその先へ気が回ることがありませんでした。 対して、DeployGate ではやるべきタスクを考えるときはいつも「ユーザ数を増やすために何をすべきか」「より(ユーザの)開発を爆速化するために何をすべきか」といったことが念頭に置かれていました。
「自分が技術的にやりたいこと」と「タスクの優先順位」「リソースの制約」のバランスにはインターン中悩まされました。 難しいです。 ただ、こう悩めたことについてもインターンに参加した意味はあったように思います。
その他
勤務スタイル
東横線が若干空いてくる10時出勤で、普通に私服でした。 無限コーヒーがあったので毎日飲んでいました。
飯事情
ミクシィは渋谷の東にありますが*4、周りの飯屋に関してはさすが渋谷といった所で充実していました。 オールジャンルに、20数件はランチとか帰りの晩飯で食べ歩きました。 ランチは DeployGate グループ以外に、他部署の人と行くこともよくありました。
最後に
自分を受け入れてくださった DeployGate グループの方々、本当にお世話になりました。 皆さんのお陰で終始楽しく開発できました、ありがとうございました!!
また、いろんな機会にお話させていただいた他部署の方々、今回このような機会を設けて下さった人事の方々に感謝致します。
1ヶ月参加して学ぶことも多く、まさにインターン充実していたように思います。 ネット上で見ただけであった Web 業界の開発現場を肌で感じられたのは大きかったです。
最高の夏でした!!!!
mado: Markdown をリアルタイムプレビューするツール作った
Markdown のリアルタイムプレビューを行う mado というツールを作った。 世の中 Markdown Previewer なんてごまんとありそうだけど、とりあえず作った。
特徴
Web ブラウザ上で Markdown をプレビュー
Markdown を HTML 整形したものを Web ブラウザ上でプレビューできる。 Github Flavored Markdown に対応している。 好きなエディタで編集しつつ、横にブラウザを開いてどんな出力になるかを確認しながら使う感じ。
また、プレビューの見た目は Github 上での Markdown プレビューになるべく似せるようにしている。 Github に上げるプロジェクトの README.md を編集するのに便利ではないだろうか。
ちなみに、Github ライクな見た目の実現には github.css に手を加えたものを使用している。
Markdown ファイルの変更を検知して、プレビューをリアルタイムに更新
Markdown ファイルを編集すると、WebSocket を通じてプレビューがリアルタイムに更新される。 リロードする必要はない。
シンタックスハイライト
fenced code-block (バッククォート3つで囲むやつ) に書いたコードはシンタックスハイライトされる。 ハイライトの色は Github 上での色に準じている。
相対パス画像展開
ローカル上にある画像を相対パス指定で表示することができる。

スクリーンショット
インストール
gem として提供している。
$ gem install mado
起動
mado はコマンドラインツールである。 編集したい Markdown ファイルを指定して起動する。
$ mado README.md [-p PORT] [-h HOST]
デフォルトでは8080番ポートで Web サーバが立ち上がる。
Web ブラウザで http://localhost:8080 を開くと、README.md の HTML プレビューが表示される。
あとは好きなエディタで Markdown を編集するだけ。
変更に追従してプレビューが更新される。
今のところ、WebSocket サーバが8081番ポート固定で立ち上がるので注意が必要。 どうにかしたい。
TODO
- チェックリスト対応
[ ] hogeみたいなやつ
- WebSocket サーバのポートをパラメータ化する
- 固定は良くない
ソースコード
Issue & PR お待ちしております。